Jim English
John Welsh Centennial Professor of English; Director, Wolf Humanities Center; Faculty Director, Price Lab for Digital Humanities
John Welsh Centennial Professor of English; Director, Wolf Humanities Center; Faculty Director, Price Lab for Digital Humanities
Digital Humanities Specialist, Penn Libraries
CAS '18 (English, Statistics)
Phase I
Co-investigator: Chris Jimenez, Ph.D. Candidate, English
Scholars of contemporary fiction face special challenges in making the turn toward digitized corpora and empirical method. Their field is one of exceptionally large and uncertain scale, subject to ongoing transformation and dispute, and shrouded in copyright. The CFDB project represents one possible way forward, using quantitative relationships among mid-sized, hand-made datasets with richly informative metadata to map the field of Anglophone fiction from 1960 to the present.
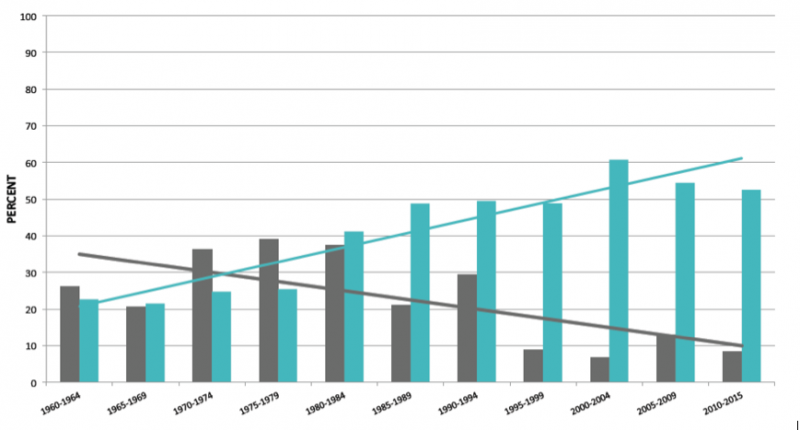
Some significant findings of this research concern a shift in the typical time-setting of the novel and a concomitant change in the relationship between literary commerce and literary prestige. The first phase of this research, supported by the Price Lab, is part of an international project on Scale & Value: New and Digital Approaches to Literary History, and will be published in a special issue of Modern Language Quarterly co-edited by Jim English and Ted Underwood.
Phase II
Off-campus collaborators: Chicago Text Lab, Stanford Literary Lab
In the first phase of the CFDB project we performed statistical comparisons between bestsellers and prize-nominated novels, year by year, 1960 to the present. The analysis relied entirely on hand-coded metadata; there was no computational “distant reading” involved. That work produced one important finding: a dramatic shift of the field of contemporary fiction around the year 1980, after which it becomes much more likely that a novel nominated for a major prize is set in the past, and much more likely that a novel on the bestseller list is set in the present or the future. The second phase of the project aims to dig further into that fulcrum point around 1980 by building a digitized corpus of contemporary fiction and subjecting it to computational analysis. A combination of Price support and collaboration with colleagues at Chicago Text Lab and Stanford Literary Lab, has enabled us to acquire a CFDB library of nearly 1,000 digitized novels. We have prepared these for text mining and conducted some initial experiments. One outcome is a computational method for predicting with 77% accuracy whether or not the main action of a given contemporary novel is set more than 35 years prior to its publication date. We are currently exploring differences between pre-1978 and post-1982 novels.